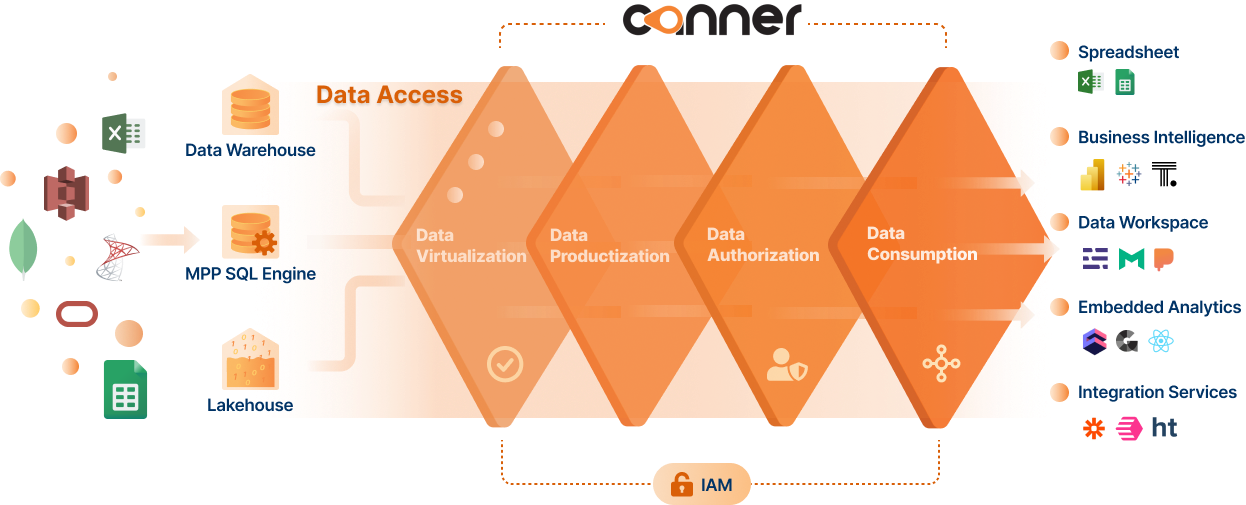
Data Mesh 架構下的資料調用層
資料調用層的建置,在 Data Mesh 的架構下要能夠符合複雜的資料運算與取用上需延伸到以下特質:
- 大數據聯合運算: 能夠串連大數據的各式運算系統包含 MPP 大數據架構下的資料分析引擎,以及各式資料倉儲與資料湖運算引擎連結。
- 同質化的元數據: 橫跨異質的資料來源與資料模型,包含資料庫、資料倉儲以及資料湖,連結並且同質化元數據 (Metadata)。
- 一致的資料授權: 資料應用與儲存運算能夠與內部的身份與人員權控整合,包含像是 Azure Active Directory, Okta 以及 OpenID, LDAP。
- 資料定義與指標: 資料定義與指標在不同的協作群體間,都能夠透過一致開放的資料交換介面,讓資料使用者能夠交換以及合作。
- 應用工具取用優化: 能夠建置 Pre-aggregate 資料分析資料集與 Cubes 讓資料在取用時能夠加速,避免無謂的資源浪費。
資料調用層的設計與目標為了解決,企業內部在資料、人、應用工具中間的斷層。
資料調用四大設計
為了達成以上的設計理念,資料調用有四大設計:
1. 資料虛擬化
首先需要多種異質資料連結器,讓異質資料儲存同質化,不論資料儲存在各種不同的資料儲存技術,包含資料湖、資料倉儲、SQL 引擎或是資料庫等,都可以透過資料連結器同質化在一個一致的資料介面上操作。
最後在資料運算時能在資料『零搬移、零複製』的情況下,把資料在運算記憶體中運算完成後直接輸出到應用端。
2. 資料產品化
在資料做加工變成,可以應用的數據的過程包含賦予他語意上、情境化的數據,叫做資料產品化。數據轉換層將指標 (Data metrics) 加入商業語意 (Semantic),讓資料集具業務性輪廓,讓資料賦予應用端語言,應用端使用者能夠定義、查找、並且理解資料來源與品質。
3. 資料授權管理
當資料從源頭的資料源權控,對接到企業內部的 Identity and Access Management 身分識別系統 (IAM),並且針對不同應用軟體中的資料權限管理,需透過一層資料授權管理層做串接,讓資料能夠與組織內部的權限管理進行整合。
4. 自助式調用
透過廣泛支援的資料輸出方式,在各種不同的業務場景所使用的工具,無論是營運性、分析性、整合性工具都能夠過單一平台進行優化,並且讓使用者能夠自助式管理。在應用的接口,除了支援最廣泛的 PostgreSQL wire protocol 標準介面 (PostgreSQL wire protocol 是全世界最通用且全開源的介面規格) 以外,也支援 Data API 介面讓應用工具的使用透過 API 能夠讓非 SQL-based 的嵌入應用得以使用並優化其使用場景。
資料兩端的『資料擁有者 (Data Owner)』與『資料使用者 (Data Consumer)』,透過單一資料調用框架做到安全與高效的資料使用。