Canner Enterprise
Self-service Data From
Empower your entire organization with self-service data access from anywhere.
Learn More 
Why Canner Enterprise?
In minutes
Days or Weeks
Canner centralizes governance and control across data applications, allowing for unified access to diverse data sources. We offer a more efficient and effective way to manage and govern data, reducing complexity and risk while providing greater transparency and control.
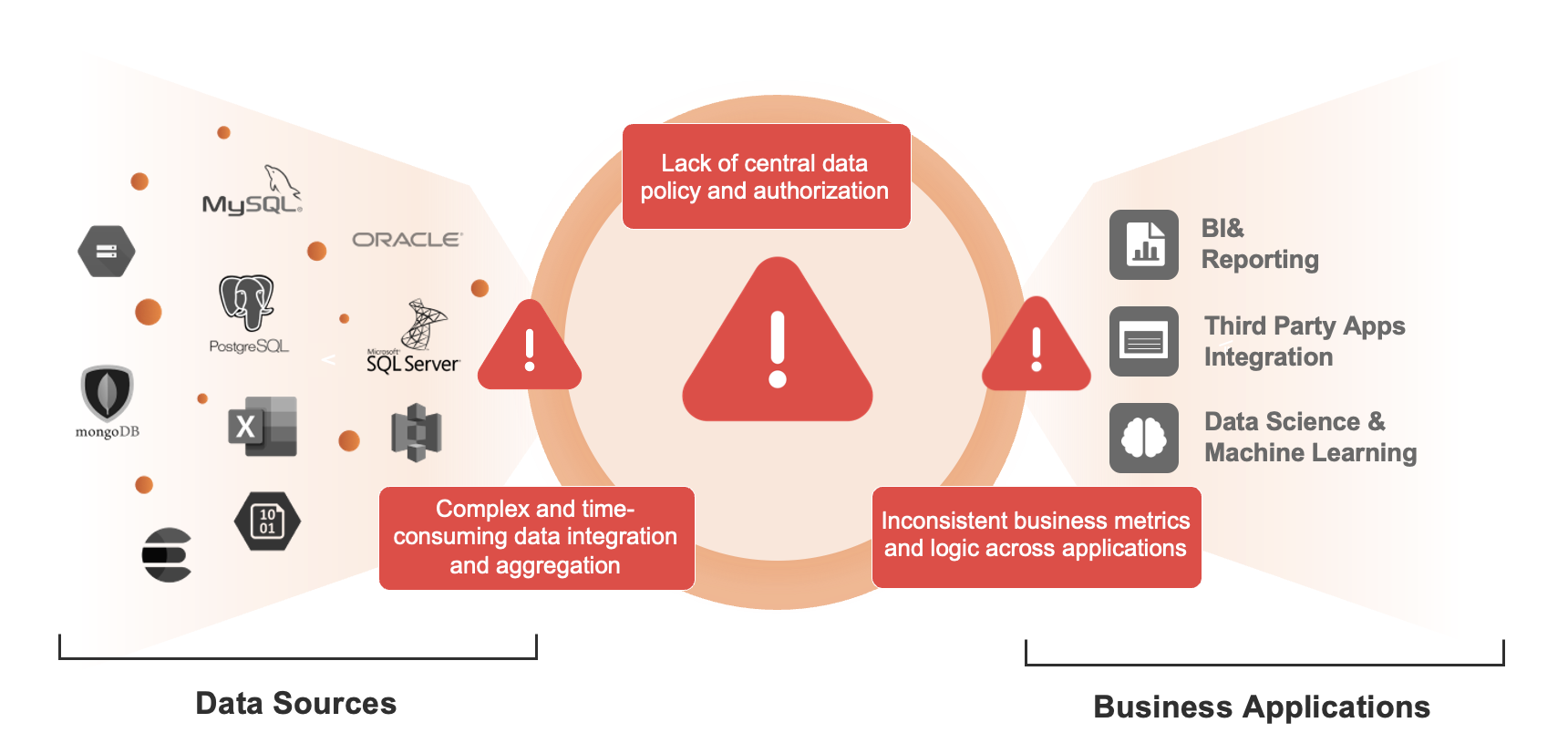
Enterprises face challenges with the complex and time-consuming data access workflow. The major pain points include lack of centralized data policy and authorization, time-consuming data integration and aggregation, and lack of agreement on business metrics between departments.
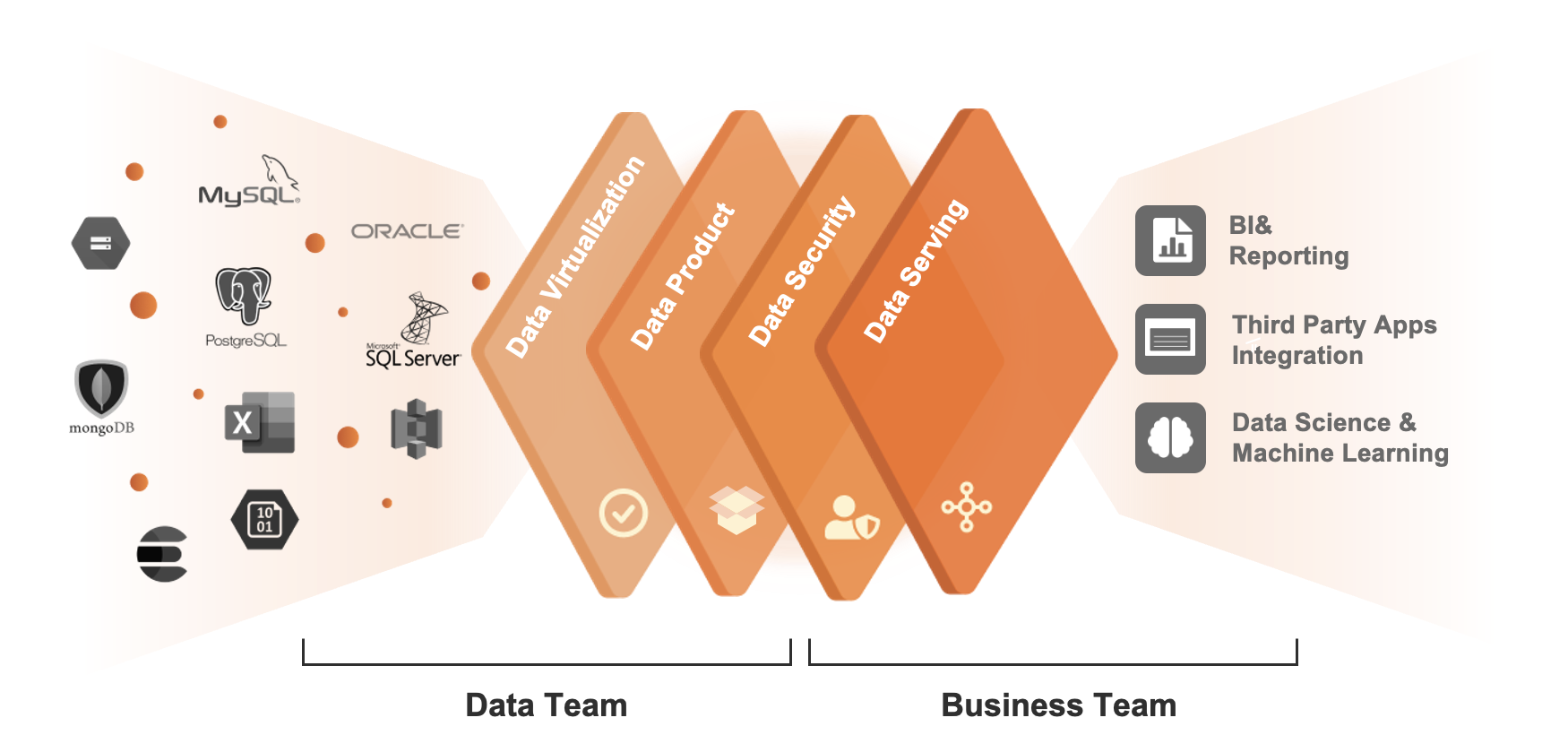
Data Virtualization
Data Product Management
Data Security
Data Serving
1Data Virtualization
Virtualize and normalize metadata from sources
Canner Enterprise can aggregate data across multiple data models with a data virtualization layer over data lakes, data warehouses, and siloed SQL data sources.
Through Metadata Manager, Canner will scan and map data schema, and types, with data literacy in one place, to make sure data’s definition is consistent across tools, and storages.
Keep track of data changes in upstream sources to prevent unpredictable downtime in downstream services and applications.
2Data Product Management
Enable self-service ability for business teams and users.
Add descriptions, and labels on the customizable database, table, and column names. Constructing data directories for availability and searchability
A built-in data search engine for organizations, groups and data owners that can be customized, whether a dataset is locally or publicly searchable for certain authorized groups and users.
Canner Workspaces are virtualized data workspaces that combine and compose analytic data metrics with operational-oriented datasets created by the data domain owner.
Configure data caches machinations based on different business scenarios, query data by ad-hoc, batch, or incremental updates.
3Data Security
Unified data authorization and data policy across sources and data applications.
Govern collaborative datasets for authorized users as well as revocation of rights as they are propagated.
Based on different data consumers' profiles, domain owners can set up global and local data masking for data privacy governance.
Canner provides personal access tokens that can be used in place of the original password authentication method to provide enterprises with a more secure way to access data using external APIs.
User's data behaviors will comprehensively log in the system, such as activities, user login, operations, and queries, to ensure data follows the company's policies.
4Data Serving
Standardize metrics definition and business logic.
Support abundant RESTful API, Scala, Python, JDBC/ODBC, CSV, excel that most data consumers needs.
Canner Protocol comply with PostgreSQL wire protocol standard, and thus, supports popular BI tools and can natively work with any ETL, IDE, drivers, and tools that support the PostgreSQL connector for data services to provide fast and secure queries.
Canner support dedicated connectors to popular BI tools: Tableau, in simple steps, and built-in data automation to make sure data is up-to-date.
Improve Data Efficiency and Reduce Cost
0%
Eliminate data copying
Reduce duplicate datasets
Reduce duplicate datasets
Data Engineering Performance 
10X
Create data products
Achieve self-service analytics
Achieve self-service analytics
Data Analytics Productivity
5X
Up-to-date reports
Agile and Accurate
Agile and Accurate
C-Level Decision-making
Start using Canner Today
Learn More