
Nowadays, enterprise data is very complex siloed, and scattered across many different data sources and systems. Being able to retrieve and collecting the holistic data overview is becoming a huge task. Companies need to have a new approach to solve and apply to their data ecosystem, that is “Data Fabric”.
What is a Data Fabric?
Conceptually, Data Fabric is an abstraction layer across all the data sources, to empower data teams to collect data information across different sources. Data Fabric is a distributed data environment that connects all data together so that it can be seamlessly accessed by data management services and utilized by end-users, or by applications, and more importantly, data is not physically moved, it is connected by a virtual layer.
Here’s the Data Fabric definition from Gartner.
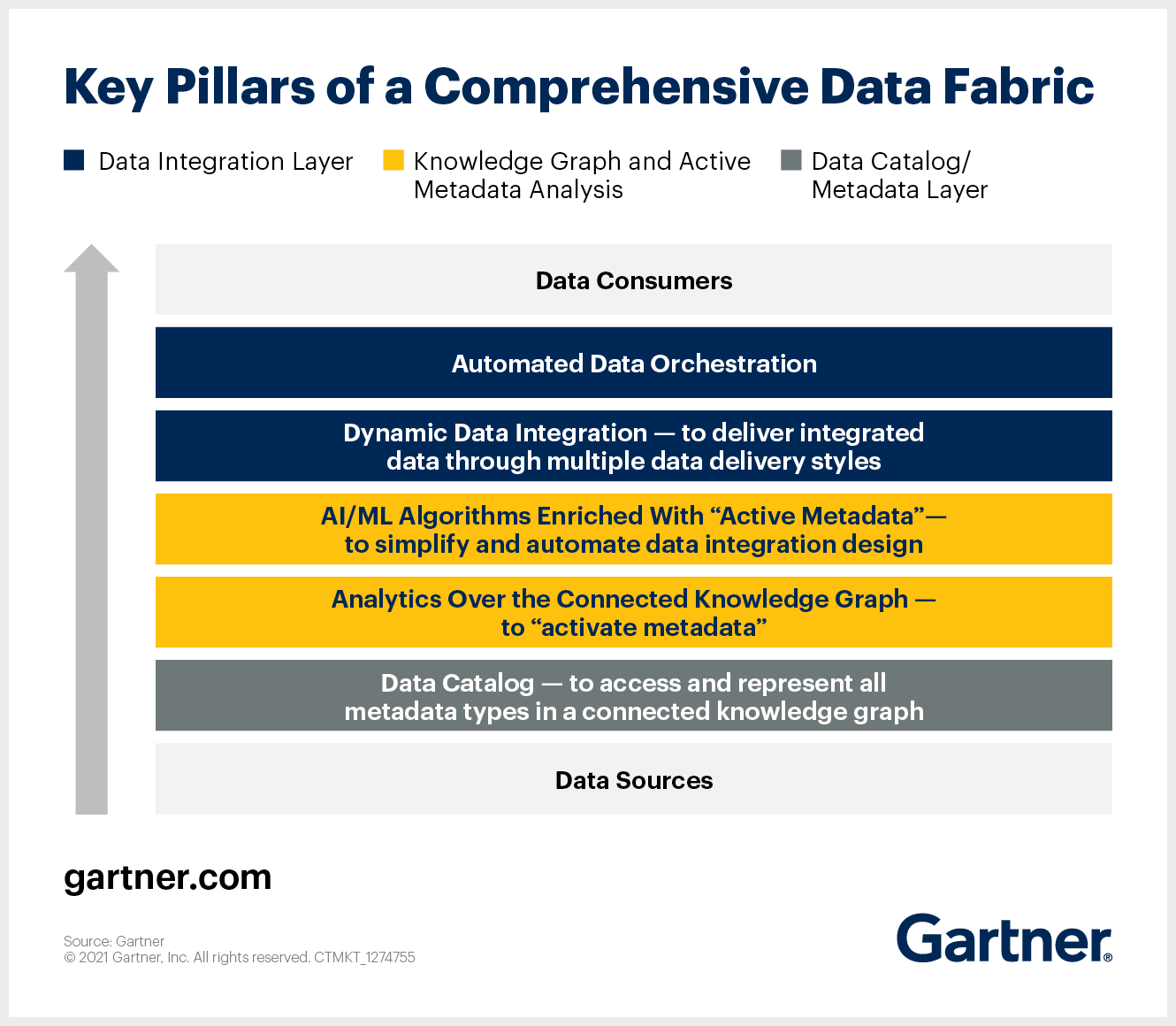
Source From Gartner Data Fabric Architecture is Key to Modernizing Data Management and Integration
Key features
Seamlessly integrated with your existing data architecture.
The Data Fabric must capable of integrating existing data architecture and data sources, by simply connect to the sources. Data sources may be public clouds or on-premises, Data Fabric technology needs to provide a single layer for data access and delivery, this way data silos can be connected through a virtual layer.
Robust data outputs and destinations
Through the Data Fabric complex data transformation and optimization, end-users are able to connect to different outputs such as AI, BI, and analytics software.
Metadata catalog and management
In Data Fabric software one of the most important features is metadata catalog, which allows data to be searchable, downloadable and all business users can easily access and share between different units and departments.
Flexible data modeling and transformation
Using Data Fabric it is also very easy for users to model and transform their data into different dimensions, so different business users are able to inspect and review the data in different aspects and scenarios.
Data sharing & protection
Data sharing within an organization and the cross-functional departments is a huge challenge, most enterprises will encounter huge data management bottlenecks while they are scaling their data pipelines. Also, data protection between each user will need a fine-granular permission layer (schema, table, column-level of access control), a built-in user/role-based permission system, and versioning.
Canner
With Canner data access solution, enterprises can connect data silos virtually, and accelerate business data analysis, while ensure data privacy, with data policies.
- Connect with data sources in clicks.
- Optimization for data outputs
- Metadata management
- Data transformation
- Virtual data mart for data sharing & protection.
No reproduction without permission, please indicate the source if authorized.