
Introduction
The growth of data innovation has exploded in recent years, mainly due to the thriving cloud data warehouse communities such as Snowflake, Redshift, and BigQuery, with their primary focus on SQL users and business intelligence use cases. Lakehouse architecture brings analytics closer to data lakes, enabling heterogeneous and distributed data processing engines to ingest sources, including diverse workloads such as data science, machine learning capabilities, and near real-time analytics enablement. It has also spawned thriving innovations in integrated data services that automate and unify data modeling, transformation, and metrics, such as dbt and LookML. Collectively, these tools lay the foundation upon which next-generation operational and analytical data applications can be constructed for various data consumers of different personas.
The Data Access Challenges
First of all, let's look at the ultimate goal for data access in a company:
Allow data consumers to find and access their data, fast and simple.
Let's look at a company's current data access workflow; here's what it looks like for a data consumer requesting and accessing data.
- Data consumers need to find who owns the data.
- Request access from the data owners; then, they must filter or mask certain rows and columns to specific groups or users before exposing them to usage.
- Based on different data applications/tools, such as using Excel, BI, AI, or RESTful API, data owners need to evaluate the best data access method.
- Last is automation. Periodically, update and deliver to end applications and ensure they are secure and auditable.
Data access in an enterprise encounters several challenges.
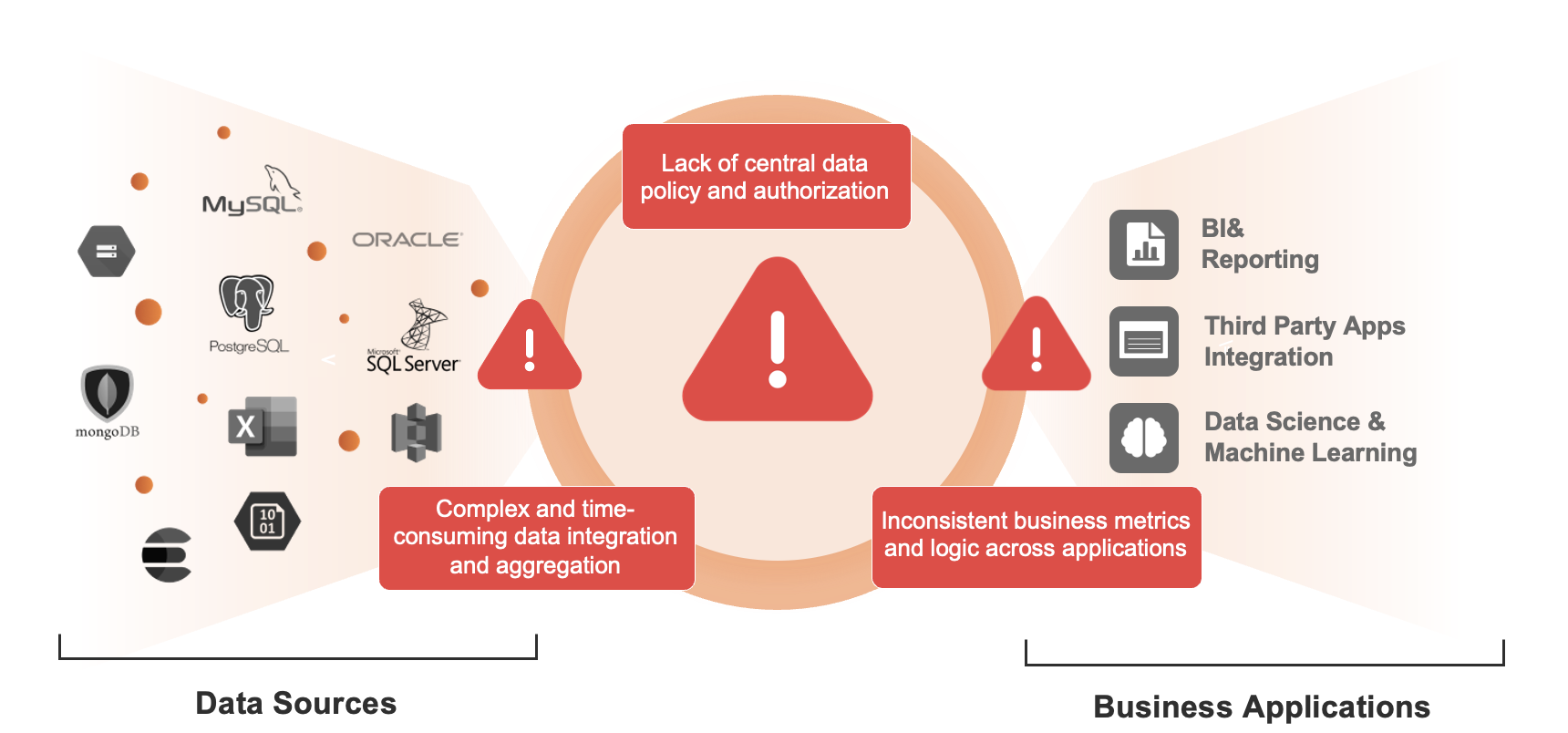
From left to right, the data heterogeneity needs to homogenize in the metadata and logical level; data authorization is a sophisticated access control and authorization for domain-specific datasets and their associated data applications; empower datasets with semantic meanings through the process of data productization; Finally, based on different data consumers' persona provide endpoints.
A Universal Semantic Layer must solve data heterogeneity, usability, and authorization while enabling consistency and scalability across different data applications.
The Universal Semantic Layer
As companies scale, they can quickly become overwhelmed with data requests, leading to a backlog of demands that can take days or even weeks to resolve. The issue lies in the data access workflow. To overcome this bottleneck, a secure, efficient, and intelligent Universal Semantic Layer is essential, enabling data consumers to access data independently, avoiding delays and misalignment, while ensuring that data owners can authorize and audit datasets, guaranteeing that only the right individuals have access to the appropriate data.
We need a Universal Semantic Layer that is secure, efficient, and intelligent.
Ultimately, achieve equilibrium between data, people, and applications.
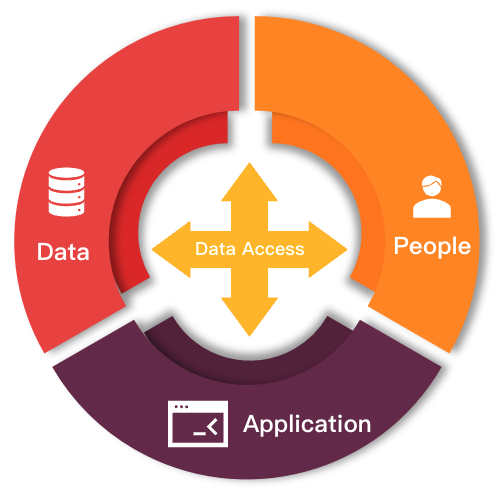
Four key designs
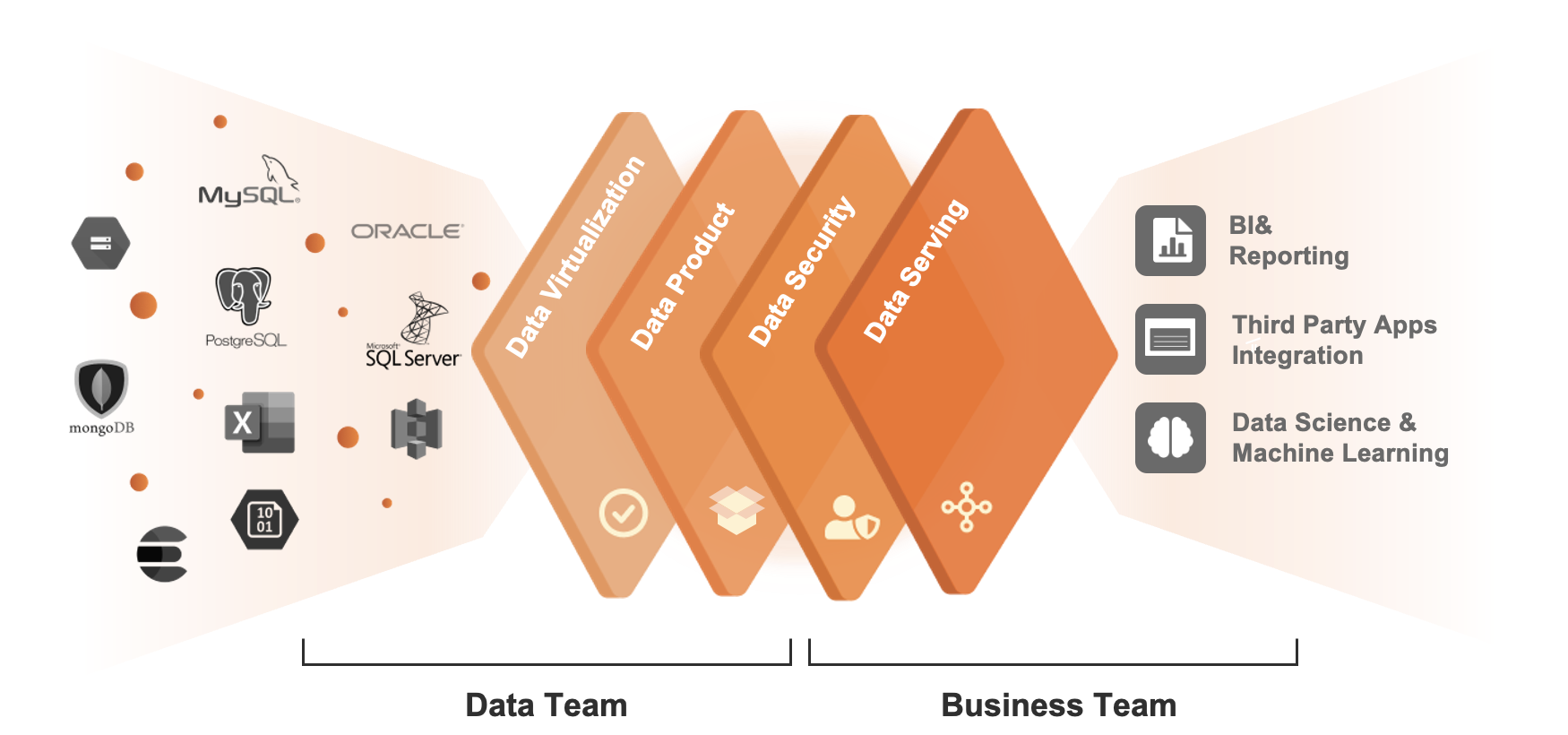
Canner Enterprise centralizes governance and control across data applications, allowing for unified access to diverse data sources. We offer a more efficient and effective way to manage and govern data, reducing complexity and risk while providing greater transparency and control.
1. Data Virtualization
Universal Semantic Layer is collaborative and distributed in nature, with each silo or data source independently scalable or together as an aggregate.
2. Data Product Management
Transform data models to domain-oriented datasets; Domain-oriented datasets owned by data owners can be shared and governed by open APIs, with the flexibility of interchangeable metadata and access rules, let data speak your business language.
3. Data Security
Consistent data authorization framework from sources to data applications and integrated with existing Identity and Access Management (IAM). Make data authorization consistent across data sources, IAM, and data applications.
4. Data Serving
Data consumers can generate Queries and APIs with intent and contextual settings, applied to the corresponding datasets via intent declaration, and deliver them to target consumers where final analytics are performed and displayed.
The Result
Enterprises can significantly eliminate data complexity, communication, and productivity through the Universal Semantic Layer.
- Data access from days to minutes: Reduce 60% of data integration cost with up-to-date data delivery.
- Reduce duplicate datasets: Create masked and filtered datasets without physically moving data.
- Achieve self-service analytics: Improve data productivity across analytical and operational data applications and tools.
No reproduction without permission, please indicate the source if authorized.